![Techgedöns [tɛçgədøːns]](https://tchgdns.de/wp-content/themes/tchgdns/images/header.png "Techgedöns [tɛçgədøːns]")

Das papierlose Büro. Wirklich ohne Papier geht es nicht; zumindest wenn es um etwaige Aufbewahrungsfristen geht und darum, dass es (leider) noch vorteilhaft sein kann, die ein oder anderen Originaldokumente aufzubewahren. Dennoch kann man den Totholzbalast auf ein Minimum reduzieren. Mein System habe ich an dieser Stelle schon einmal aufgezeigt und auch wenn dies nun schon fünf Jahre her ist, hat sich an dem Prinzip der unabhängigen Ordnerstruktur nichts geändert. Einzig und allein bei den Apps kam es zu einem Wechsel, hier bin ich inzwischen mit QuickScan unterwegs. Bei der Suche das A und O: Texterkennung oder auch OCR genannt. Bringt ja alles nichts, wenn ich zwar PDFs habe, aber in diesen nicht nach Text suchen kann – wenn man nicht jedes Detail, nach dem man vielleicht in 2-3 Jahren suchen möchte, in den Dateinamen aufnimmt.

An der fehlenden Texterkennung scheitern regelmäßig eigentlich recht solide Scanner-Apps für iOS und Android, zuletzt OpenScan. Klar gäbe es da entsprechende Tools, mit denen sich Texte in PDFs im Nachgang durchsuchbar machen (PDFify für macOS zum Beispiel), aber das ist ein zusätzlicher Schritt, den man sich auch gleich sparen kann. Wer in seinen vier Wänden ein NAS aus dem Hause Synology sein Eigen nennt, der kann mit Hilfe der DiskStation nicht durchsuchbare PDFs automatisch durchsuchbar machen. Wer bei seiner papierlosen Ablage sowieso sein NAS eingebunden hat, der muss seinen Workflow dabei auch nur minimal anpassen. Denn mit synOCR bzw. der Docker-Anwendung OCRmyPDF könnt ihr Dokumente in einem Ordner vollautomatisch durch die Texterkennung jagen.
 Bei OCRmyPDF handelt es sich um ein Open-Source-Tool, mit dem sich PDFs durchsuchbar machen. Gibt es für die DiskStation auch als Docker-Container, ist allerdings nur bedingt komfortabel zu nutzen und eigentlich nur übers Terminal zu konfigurieren. Hier kommt nun synOCR von Stephan Geisler ins Spiel: Eine GUI für OCRmyPDF, mit dem die Sache auch für Nutzer mit einem geringerem Drang zur teilweisen umständlichen Bastelei (also mich ;-)) schnell und einfach nutzbar wird. synOCR kann aber nicht nur eine Texterkennung durchführen, sondern auch nach Tags und Daten suchen, die Dateien nach einem individuellen Muster umbenennen oder in Unterordner einsortieren.
Bei OCRmyPDF handelt es sich um ein Open-Source-Tool, mit dem sich PDFs durchsuchbar machen. Gibt es für die DiskStation auch als Docker-Container, ist allerdings nur bedingt komfortabel zu nutzen und eigentlich nur übers Terminal zu konfigurieren. Hier kommt nun synOCR von Stephan Geisler ins Spiel: Eine GUI für OCRmyPDF, mit dem die Sache auch für Nutzer mit einem geringerem Drang zur teilweisen umständlichen Bastelei (also mich ;-)) schnell und einfach nutzbar wird. synOCR kann aber nicht nur eine Texterkennung durchführen, sondern auch nach Tags und Daten suchen, die Dateien nach einem individuellen Muster umbenennen oder in Unterordner einsortieren.
#1: synOCR installieren
Zunächst müsst ihr das synOCR-Paket auf eurer Diskstation installieren. Da es sich aber um ein offizielles Paket handelt, findet suche Suche im Paket-Zentrum zunächst einmal nichts. Vielmehr müsst ihr die Quelle cphub.net zu euren Paketquellen hinzufügen. Hierzu klickt ihr im Paket-Zentrum zunächst auf den Button „Einstellungen“ und wechselt dann in den Reiter „Paketquellen“:

Dort klickt ihr auf „Hinzufügen“ und gebt dort neben einem passenden Namen für die Quelle auch die oben genannte Domain „https://www.cphub.net/“ ein:

Schließt ihr nun die Fenster, seht ihr in der Seitenleiste einen neuen Menüpunkt „Community“, in dem ihr alle Pakete der Drittquellen angezeigt bekommt. Alternativ hilft euch die Suche natürlich ebenso weiter und macht das Paket synOCR nun auffindbar:

Das Paket können wir nun direkt über den Button „Installieren“ mit zwei weiteren Bestätigungen aufs NAS bringen – wer mag, der kann sich natürlich auch noch ein paar Paketdetails anzeigen lassen, diesen Punkt überspringe ich aber einfach mal. Die Installation in ein paar Sekunden erledigt sein. Rufen wir nun unsere installierten Pakte auf, so sollten wir dort einen neuen Eintrag für synOCR vorfinden.

#2: synOCR konfigurieren
Wie üblich muss synOCR natürlich zunächst konfiguriert werden, was je nach Anspruch und Bedürfnis unterschiedlich aufwendig ausfallen kann. Wichtigste Einstellung: Die Angabe der Quell- und Zielordner auf eurem NAS. Sprich in welchen Ordnern soll synOCR nach PDFs suchen und wo sollen diese abgelegt werden. Hierbei müsst ihr darauf achten, die kompletten Pfade inkl. Volume (z.B. /volume1/…) einzutragen und auch die korrekte Groß- und Kleinschreibung ist relevant. Ebenso könnt ihr einen Backup-Ordner definieren, in welchem die Originaldateien gesichert werden – ansonsten werden diese nämlich unwiderruflich nach Durchführung der Texterkennung gelöscht:

Für den Schnelleinstieg ebenfalls nicht unwichtig ist das Setzen der OCR-Optionen, insbesondere der Sprache. Diese Möglichkeit findet ihr unter dem Punkt „OCR Optionen und Umbenennung“. Empfohlen wäre hier mindestens ein „-l deu+eng“ um die Spracherkennung für Deutsch und Englisch zu nutzen:

Die restlichen Optionen und Parameter sind optional, aber durchaus einen Blick wert. Beispielsweise könnt ihr mit dem Feld „Suchmuster Quelldateiname“ nur PDF-Dateien durchs OCR jagen, die eine entsprechende Zeichenfolge aufweisen – zum Beispiel „Scan_“, wie sie die üblichen Scanner-Apps und -Tools für ihre Benennung benutzen:

Wollt ihr die OCR-PDFs auch gleich noch passend umbenennen, solltet ihr auch den restlichen Optionen Beachtung schenken. So könnt ihr in einem PDF nach bestimmten Schlagworten suchen und diese in Form von Tags in den neuen Dateinamen einfügen. Bei der Definition von Schlagworten habt ihr zwei Möglichkeiten: Entweder gebt ihr nur bestimmte Begriffe an, die mehr oder weniger für sich stehen, wie zum Beispiel „Rechnung“ oder „Abrechnung“. Ebenso könnt ihr Dateien mit bestimmten Tags auch direkt in Unterordner sortieren, beispielsweise „HUK24=Versicherung“ oder „SWK=Strom“:

Wie ihr am letzten Beispiel sehen könnt, kann synOCR recht umfangreich konfiguriert werden, sodass ihr nicht euren Workflow anpassen müsst, sondern das Tool in euren Workflow integrieren könnt. Schaut euch die Optionen einfach mal der Reihe nach an und lest euch die Hilfestellungen bei Mausüberfahrt über das Info-Icon durch. Dort ist eigentlich alles recht gut erläutert:
#3 synOCR automatisch durchführen
Auf dem Hauptscreen von synOCR könnt ihr einen manuellen Programmlauf durchführen. Beim ersten Mal benötigt der Prozess übrigens deutlich länger, da zunächst der Docker-Container von OCRmyPDF heruntergeladen und eingerichtet werden muss – die folgenden Durchläuft sind deutlich flotter. Aber man möchte natürlich nicht immer händisch die Texterkennung starten, sondern idealerweise sollte dies automatisch geschehen. Hierzu habt ihr zwei Möglichkeiten: entweder über den integrierten Zeitplaner oder den Aufgabenplaner des DiskStation Manager. Der Zeitplaner von synOCR selbst ist recht schnell eingerichtet – wahlweise mit einer einmaligen oder mehrmaligen Ausführung je Tag:

Ich persönlich bevorzuge jedoch den Weg über den DSM-Aufgabenplaner – einfach weil ich so die aktiven Aufgaben besser im Blick habe, als wenn diese „irgendwo“ im System hinterlegt sind. Solltet ihr bisher noch keinen Kontakt mit dem Aufgabenplaner gehabt haben, werft einmal einen Blick in diesen Beitrag, in dem ihr einen prinzipiellen Überblick über die Optionen erhaltet. Ist aber kein Hexenwerk, denn wirklich viele Optionen gibt es in unserem Falle nicht wirklich. Habt ihr den Aufgabenplaner über die Systemeinstellungen der DiskStation aufgerufen, könnt ihr ohne Umweg über den Button „Erstellen → Geplante Aufgabe → Benutzerdefiniertes Skript“ eine neue Aufgabe erstellen:
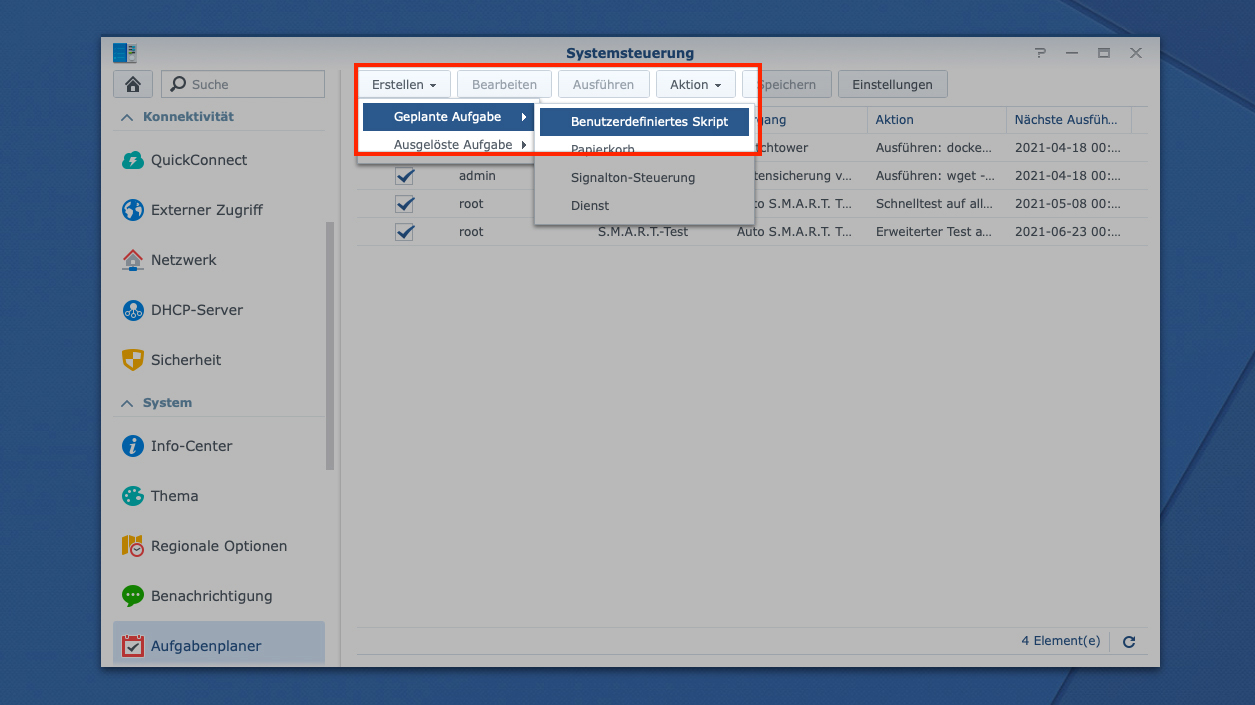
Im Reiter „Allgemein“ vergebt ihr zunächst einen halbwegs passenden und auch später leicht erkennbaren Namen, als Benutzer wählt ihr (falls nicht schon von Haus aus vor selektiert) „root“ aus:

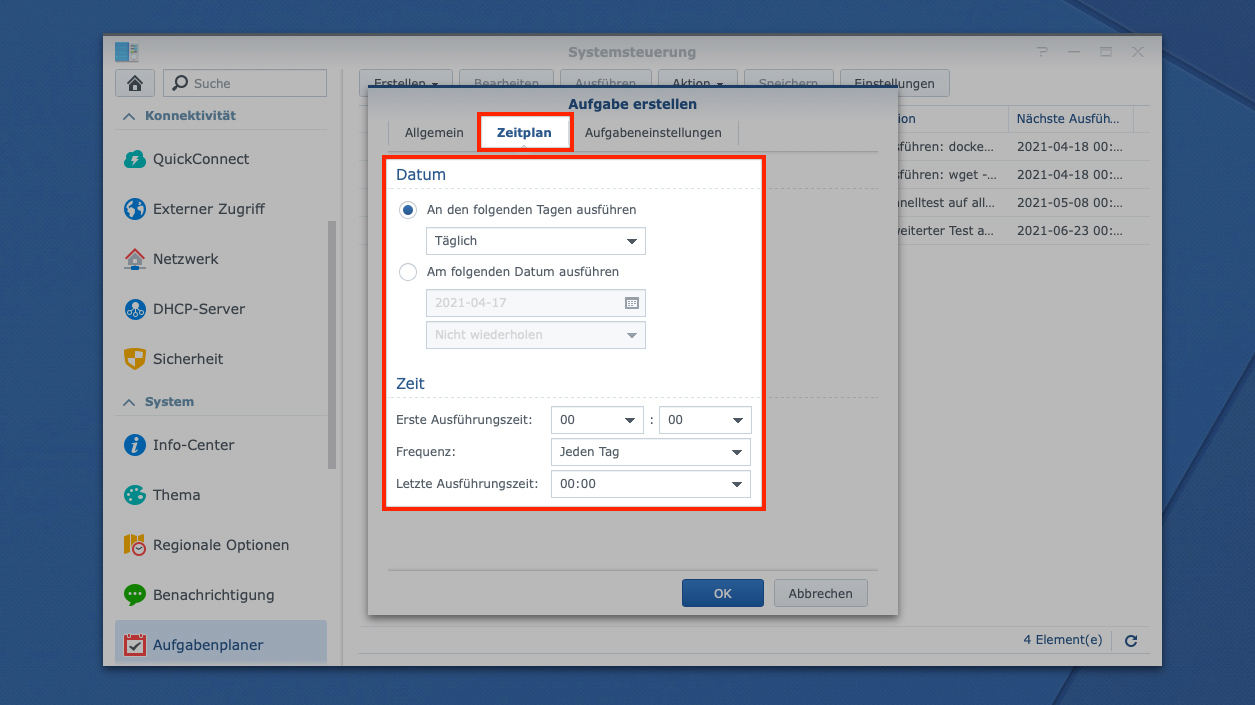
Im Reiter „Zeitplan“ könnt ihr euch natürlich nach eurem belieben austoben – immerhin bleibt es euch überlassen, wann und wie häufig ihr die Texterkennung neu abgelegter Dokumente im Quellordner durchführen wollt:
Zu guter Letzt müsst ihr im Reiter „Aufgabeneinstellungen“ noch das benutzerdefinierte Skript hinterlegen, welches im gewählten Intervall automatisch ausgeführt werden soll. Quick and Dirty: /usr/syno/synoman/webman/3rdparty/synOCR/synOCR-start.sh:

Wer bereits auf DSM 7.0 setzt, der wird vor einem nicht funktionieren synOCR stehen. Aufgrund geänderter Berechtigungen sind hier zusätzliche Schritte notwendig, die ihr im Synology Forum nachvollziehen könnt. Danke Stephan für den Hinweis!





